ML-PSF: Picking Good Sources for PSF Generation
TL;DR
We can maybe use Machine Learning (ML) to help pick stars for Point Spread Function (PSF) creation to save time in astronomy data processing pipelines.
Built With
![]()
![]()
![]()
Background
What is a PSF?
PSFs mathematically describe how point source objects are distorted in an image. Images are a convolution between the true object and its PSF.
Why are PSFs important to astronomy?
PSFs are necessary to study any object close to the resolution limit of a telescope with high precision.
What do we need in order to create PSFs?
Examples of point-like sources in the image of interest are needed as inputs to PSF generation software. In astronomy, good point-like sources would be stars that are bright, round, and well isolated from other sources. The task of selecting these good sources for PSF generation is what this deep learning model has been trained to do.
Goal
Given cutout of each source in an image along with their respective x and y coordinates, this program calls on an already trained ML model that will return a subset of cutouts of sources to use for PSF creation. It also returns the x and y coordinates of these sources that can be used to pass into the python module TRIPPy in order to create the desired PSF.
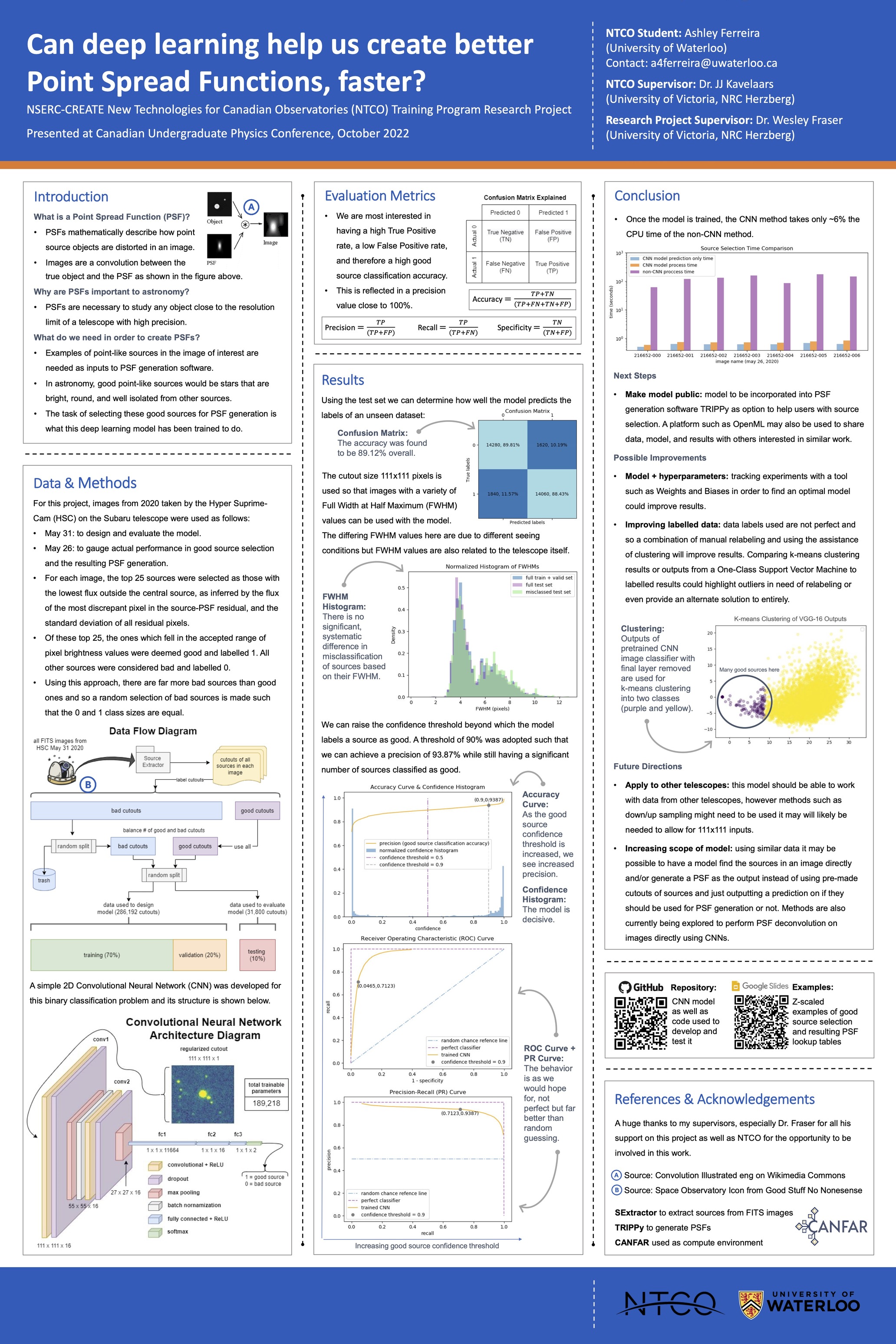
Method
For this project, images from 2020 taken by the Hyper SuprimeCam (HSC). For each image, the top 25 sources were selected as those with the lowest flux outside the central source, as inferred by the flux of the most discrepant pixel in the source-PSF residual, and the standard deviation of all residual pixels.
Of these top 25, the ones which fell in the accepted range of pixel brightness values were deemed good and labelled 1. All other sources were considered bad and labelled 0. Using this approach, there are far more bad sources than good ones and so a random selection of bad sources is made such that the 0 and 1 class sizes are equal.
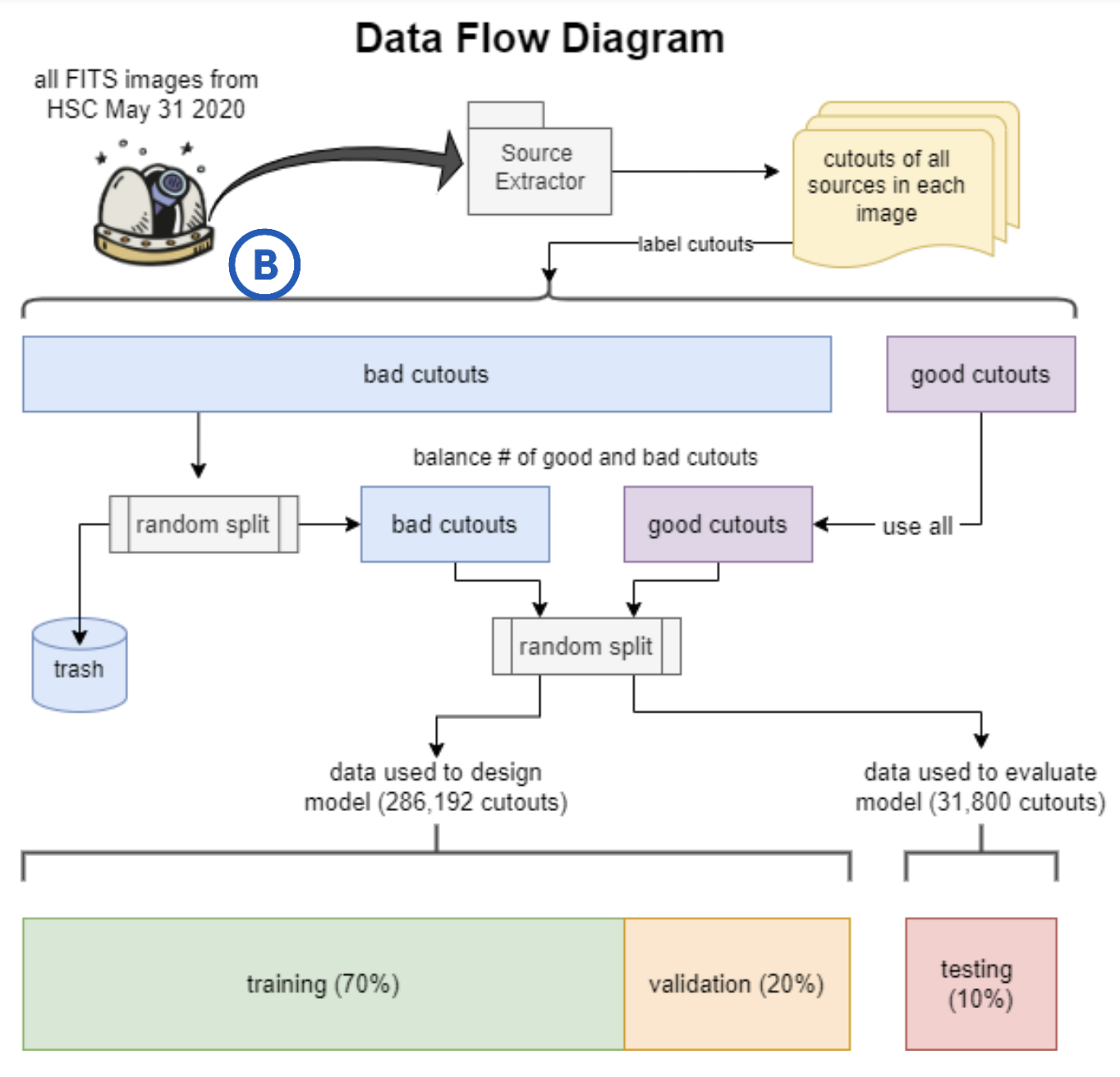
A simple 2D Convolutional Neural Network (CNN) was developed for this binary classification problem:
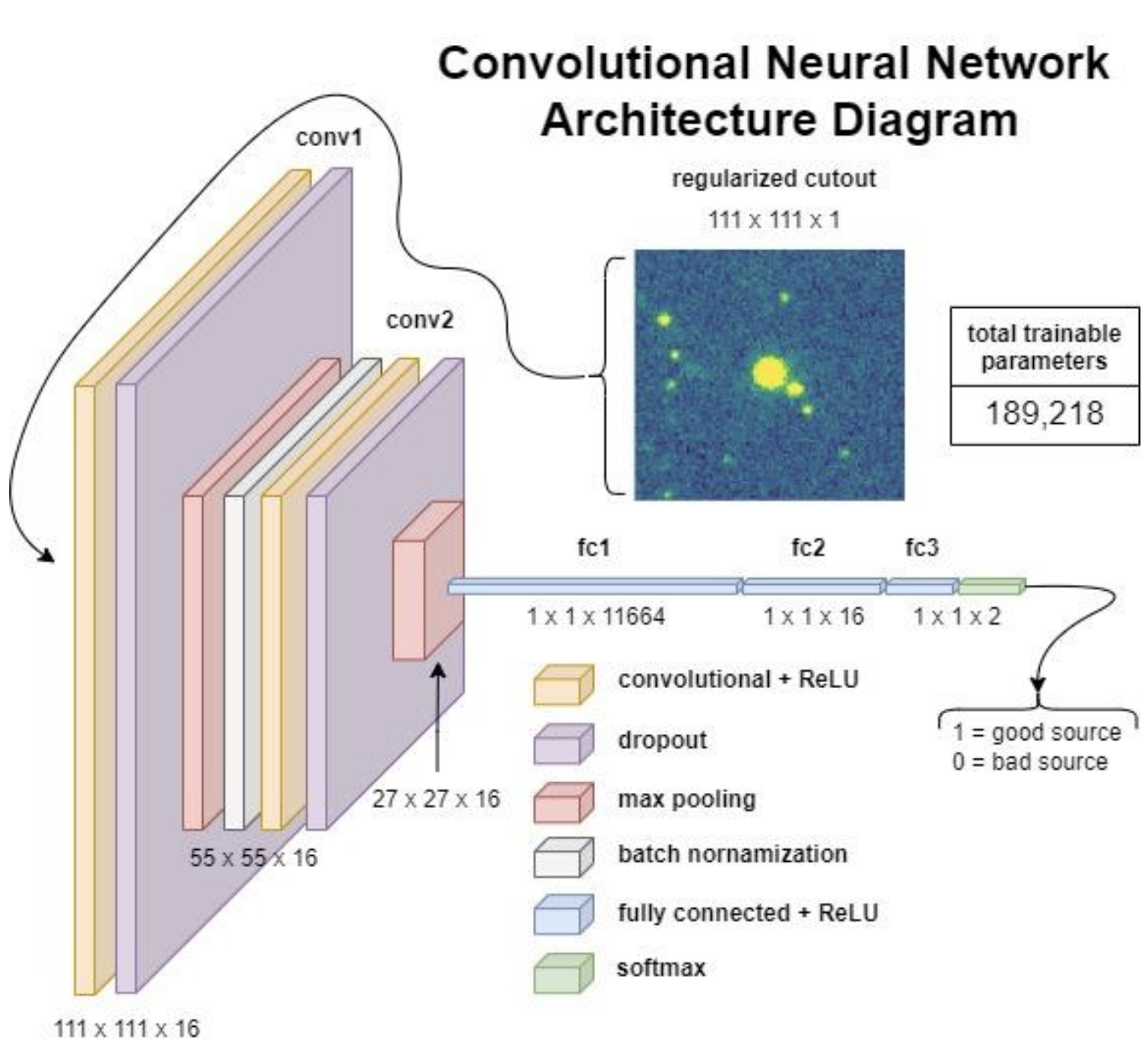
Results
The accuracy on the test set was found to be 89.12% overall.
We can raise the confidence threshold beyond which the model labels a source as good. The default threshold is 50%, however, since we care much more about achieving a low false positive rate than a low false negative rate, the threshold of 90% was adopted such that we can achieve a false positive rate of 93.87% while still having a significant number of sources classified as good:
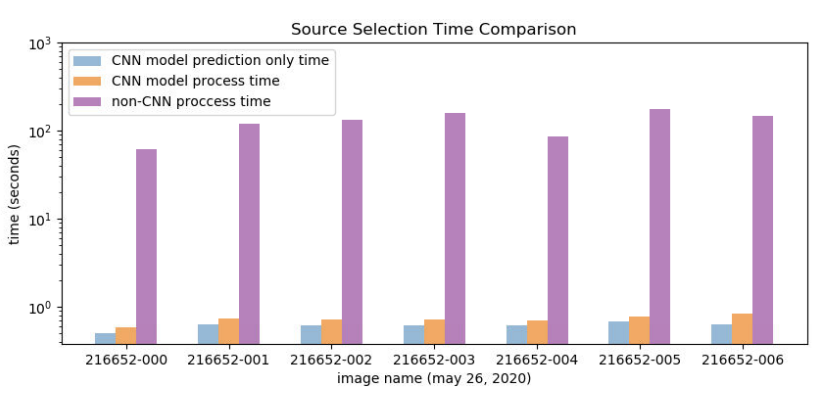
Once the model is trained, the CNN method takes only ~6% the CPU time of the non-CNN method, dramatically speeding up the pipeline:
Conclusion
This machine learning-based method allows for faster PSF generation but not nessisarily better. Some form of unsupervised learning is likely needed as a next step.
Resources
- Project is publically available on GitHub: ashley-ferreira/ML-PSF
- Poster available here